
Guía para monitorización de bots de trading automatizados

Cada día, traders experimentados pierden miles de dólares por fallos silenciosos en sus bots automatizados que permanecen sin detectar durante horas. Un bot de trading puede estar ejecutando órdenes sin confirmar stops, ignorando errores RPC o congelado en un loop infinito mientras tu capital se evapora. Esta guía te muestra cómo implementar sistemas de monitorización multinivel que detectan estos problemas antes de que destruyan tu rentabilidad, combinando técnicas de vigilancia interna y externa que reducen drásticamente el riesgo operacional en DEX perpetuos.
Tabla de contenidos
- Puntos clave
- La necesidad de una monitorización robusta para bots de trading en dex perpetuos
- Técnicas y herramientas para seguimiento multilayer de bots
- Gestión del riesgo y revisión del rendimiento en tiempo real
- Casos extremos y errores comunes en bots de trading en dex perpetuos
- Descubra Mithril Money para trading automatizado seguro
- Preguntas frecuentes
Puntos Clave
| Punto | Detalles |
|---|---|
| Monitoreo multinivel | La monitorización multinivel combina vigilancia interna y externa para detectar fallos antes de dañar la rentabilidad. |
| Verificación de acciones | Verificar cada acción crítica como la colocación de órdenes y la activación de stops evita pérdidas silenciosas. |
| Timeouts y watchdogs | Timeouts agresivos y watchdogs internos detectan bucles congelados y fuerzan reinicio o detención del bot. |
| Supervisión externa | Supervisores externos verifican heartbeats, timestamps y estados de salud para alertar sobre anomalías no vistas por el bot. |
| Selección de DEX y estrategias | La elección de plataformas DEX y tácticas determina la efectividad y el impacto de los fallos. |
La necesidad de una monitorización robusta para bots de trading en dex perpetuos
Cuando automatizas estrategias de trading automatizadas en DEX perpetuos, te enfrentas a dos categorías de fallos: los visibles que detienen el bot inmediatamente y los silenciosos que continúan ejecutando operaciones defectuosas sin alertas. Los fallos visibles son manejables porque los detectan supervisores de procesos estándar. Los silenciosos son devastadores porque tu bot parece funcionar mientras acumula pérdidas.
La monitorización multinivel con timeouts internos y watchdogs externos es esencial porque los hangs imitan crashes pero evaden monitores de procesos. Un caso real documentó un bot de trading en vivo que permaneció colgado durante 7 horas completas sin que el sistema de reinicio automático lo detectara. El bot seguía ejecutándose como proceso activo, pero su event loop estaba congelado esperando una respuesta de API que nunca llegó.
“Los fallos silenciosos son más peligrosos que los crashes porque te dan falsa sensación de seguridad mientras tu capital se erosiona sistemáticamente.”
Los procesos estándar de monitorización verifican si el bot está vivo, no si está operando correctamente. Necesitas múltiples capas de vigilancia:
- Confirmación explícita de cada acción crítica: verificar que órdenes se colocaron, stops se activaron, posiciones se cerraron
- Timeouts agresivos en todas las llamadas API para evitar esperas infinitas
- Watchdogs internos que detectan threads congelados antes de que afecten operaciones
- Supervisores externos que verifican heartbeats, timestamps de logs y puertos de salud
El impacto financiero directo es brutal. Un bot market maker que falla silenciosamente puede acumular inventario desbalanceado durante horas, exponiendo tu cuenta a movimientos adversos masivos. Un bot de arbitraje de funding que no cierra posiciones delta neutral te deja con exposición direccional no intencional justo cuando la volatilidad explota.
La confianza en tu sistema de trading automatizado depende completamente de saber que los fallos se detectan en minutos, no horas. Sin monitorización robusta, cada sesión de trading se convierte en ruleta rusa donde esperas que nada salga mal porque no tendrías forma de saberlo hasta revisar manualmente.
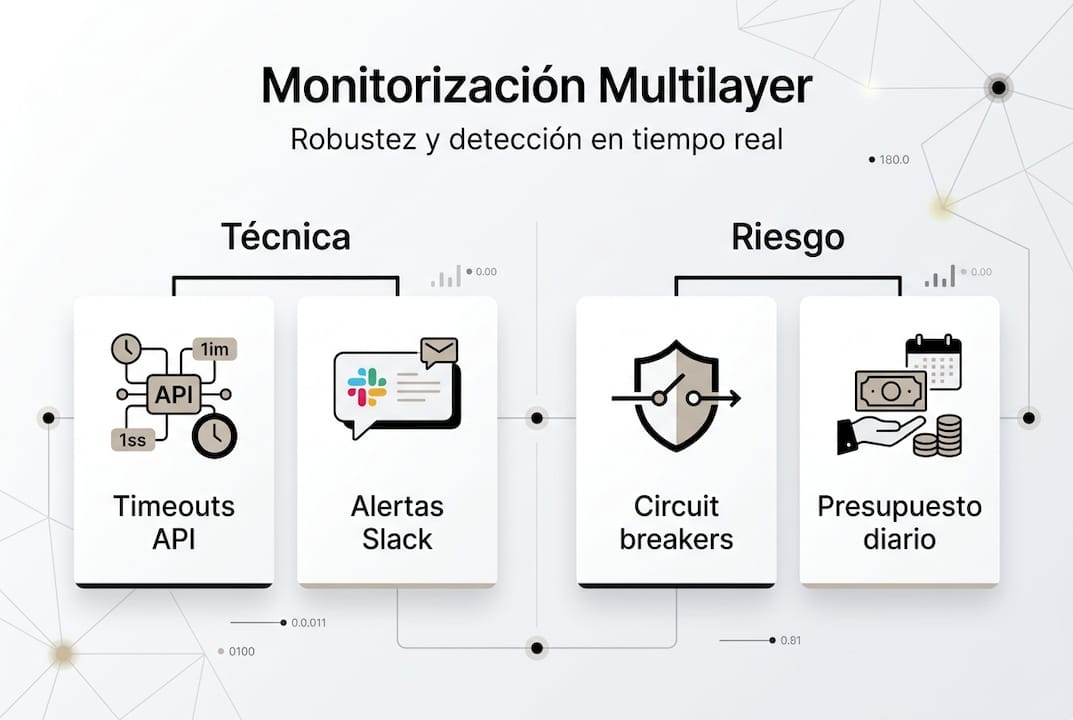
Técnicas y herramientas para seguimiento multilayer de bots
Implementar monitorización efectiva requiere combinar técnicas internas que detectan problemas desde dentro del bot con supervisión externa que verifica comportamiento desde fuera. La arquitectura correcta captura fallos en múltiples puntos antes de que causen daño real.
Para implementar timeouts en llamadas API con asyncio.wait_for en Python:
- Envuelve cada llamada a la API del exchange con asyncio.wait_for especificando timeout de 10-15 segundos
- Captura asyncio.TimeoutError y registra el fallo con timestamp exacto y contexto de la operación
- Implementa reintentos exponenciales con backoff para errores temporales de red
- Después de 3 fallos consecutivos, activa alerta crítica y considera detener trading
- Mantén contadores de errores por tipo para identificar patrones de degradación del servicio
Los watchdog threads internos detectan event loops congelados ejecutando un thread separado que verifica timestamps de actividad del loop principal. Si el timestamp no se actualiza en 60 segundos, el watchdog fuerza un reinicio del bot completo.
La monitorización externa con demonios como Horus funciona verificando tres señales:
- Heartbeats: el bot debe actualizar un archivo o endpoint cada 30 segundos
- Staleness de logs: los logs deben tener entradas nuevas en los últimos 2 minutos
- Health checks de puerto: un endpoint HTTP debe responder con estado 200 y métricas actuales
Consejo profesional: Configura alertas progresivas donde advertencias menores van a Slack pero fallos críticos activan llamadas telefónicas o SMS. Un bot colgado a las 3 AM necesita intervención inmediata, no un mensaje que leerás por la mañana cuando ya perdiste miles.
| Técnica | Ventajas | Desventajas |
|---|---|---|
| Timeouts API internos | Detecta hangs en llamadas específicas, fácil implementar | No captura loops congelados fuera de llamadas API |
| Watchdog threads | Detecta cualquier congelamiento del event loop principal | Overhead adicional de thread, puede tener falsos positivos |
| Demonios externos | Independiente del proceso del bot, detecta crashes completos | Latencia de detección de 30-60 segundos, requiere infraestructura adicional |
| Health check endpoints | Permite verificación remota y dashboards en tiempo real | El bot debe estar funcional para responder, no detecta algunos fallos internos |
La combinación de estas técnicas crea redundancia donde si una capa falla en detectar un problema, otra lo captura. Las herramientas para trading automatizado profesionales integran estas capas desde el diseño inicial, no como parches posteriores.

Configurar reinicios automáticos requiere balance: demasiado agresivo y reinicias por fluctuaciones normales, demasiado permisivo y los fallos reales pasan desapercibidos. Establece umbrales basados en severidad: timeouts de API permiten 3 reintentos, watchdogs permiten 1 minuto de inactividad, health checks externos permiten 2 minutos antes de forzar reinicio.
Gestión del riesgo y revisión del rendimiento en tiempo real
La monitorización técnica detecta fallos operacionales, pero necesitas integrarla con métricas financieras para controlar riesgos reales. Un bot que funciona perfectamente a nivel técnico puede estar destruyendo tu cuenta si los parámetros de riesgo están mal configurados o las condiciones de mercado cambiaron.
Los dashboards actualizados para revisar resultados diarios deben mostrar P&L acumulado, drawdown actual versus máximo histórico y presupuesto de riesgo consumido. Revisar estas métricas cada mañana antes de que los mercados abran te permite ajustar exposición antes de que problemas pequeños se conviertan en desastres.
Las métricas clave que todo trader automatizado debe monitorizar en tiempo real:
- P&L diario y semanal: detecta deterioro de rendimiento antes de que sea irreversible
- Drawdown actual: porcentaje de pérdida desde el pico más reciente de capital
- Presupuesto de riesgo: cuánto de tu pérdida máxima aceptable has consumido
- Sharpe ratio móvil: identifica si la relación riesgo/retorno está degradándose
- Win rate y profit factor: cambios súbitos indican que tu estrategia dejó de funcionar
Los circuit breakers detienen trading automáticamente cuando se alcanzan límites predefinidos. Si tu drawdown máximo aceptable es 15% y alcanzas 12%, el bot debe reducir tamaño de posición a la mitad. Si llegas a 15%, debe detenerse completamente hasta revisión manual. Estos límites te protegen de la tentación de “dejar que se recupere” mientras las pérdidas se aceleran.
Usar indicadores técnicos como ATR para ajustar tamaño de posición dinámicamente previene sobreexposición durante volatilidad extrema. Cuando ATR de 14 períodos aumenta 50% sobre su promedio, reduce el tamaño de tus posiciones proporcionalmente. Los movimientos grandes pueden activar tus stops más frecuentemente, pero evitas liquidaciones catastróficas.
Consejo profesional: Establece un presupuesto de riesgo diario además del mensual. Si pierdes 3% en un día, detén trading hasta el siguiente día incluso si tu límite mensual es 15%. Las pérdidas concentradas en pocas horas indican condiciones de mercado que tu estrategia no puede manejar, y continuar solo acelera la destrucción de capital.
La gestión de riesgos automatizada debe ser tan robusta como tu lógica de entrada y salida. Un sistema que genera señales perfectas pero no controla exposición es como un auto deportivo sin frenos: impresionante hasta el primer obstáculo.
Integrar alertas de rendimiento con monitorización técnica crea un sistema completo donde sabes tanto que tu bot está funcionando como que está operando dentro de parámetros seguros. Una alerta de “bot funcionando pero perdiendo 2% por hora” es tan crítica como “bot colgado sin responder”.
Casos extremos y errores comunes en bots de trading en dex perpetuos
Los fallos más costosos son los que tu monitorización no anticipa porque asumes que ciertos escenarios no pueden ocurrir. Los casos extremos incluyen fallos silenciosos como stops no confirmados, errores RPC parciales, loops de eventos congelados y divergencias de oráculos que activan liquidaciones inesperadas.
Los fallos silenciosos que no detienen el bot pero aumentan pérdidas incluyen:
- Stop loss colocado pero no confirmado por el exchange: tu bot cree que está protegido mientras la posición sigue expuesta
- Órdenes parcialmente ejecutadas que el bot marca como completas: inventario desbalanceado que acumula riesgo direccional
- Errores de redondeo en tamaños de posición que violan límites de apalancamiento: te acercas peligrosamente a liquidación sin saberlo
- Timestamps desincronizados entre bot y exchange: órdenes rechazadas por “demasiado antiguas” mientras tu bot piensa que acaban de enviarse
Los principales errores RPC y sus efectos son especialmente problemáticos en redes congestionadas. Un error “nonce too low” puede indicar que una transacción anterior no se procesó, pero tu bot ya avanzó a la siguiente operación asumiendo éxito. Errores “insufficient funds” intermitentes sugieren que el exchange está calculando margin disponible incorrectamente durante alta volatilidad.
Errores RPC parciales no tratados correctamente causan loops infinitos donde el bot reintenta la misma operación fallida indefinidamente sin registrar el problema o escalar a intervención manual. Después de 10 reintentos fallidos, el bot debe asumir que hay un problema fundamental y detenerse, no continuar intentando hasta que el watchdog externo lo mate horas después.
Las divergencias de oráculos ocurren cuando el precio de referencia del DEX se separa temporalmente del precio spot real debido a latencia de actualización o manipulación del feed. Tu bot puede ver una oportunidad de arbitraje que no existe realmente, o peor, puede ser liquidado porque el oráculo reporta un precio que activa tu límite de liquidación aunque el precio real esté seguro.
Los congelamientos de eventos suceden cuando el exchange deja de emitir actualizaciones de WebSocket pero mantiene la conexión abierta. Tu bot piensa que está recibiendo datos en tiempo real cuando en realidad está operando con información de hace 5 minutos. Implementa heartbeats en el stream de WebSocket donde si no recibes ningún mensaje en 30 segundos, cierras y reconectas forzosamente.
| Tipo de protocolo | Ventajas para bots | Desventajas para bots |
|---|---|---|
| CLOB (Order Book) | Slippage mínimo en órdenes grandes, ejecución predecible, ideal para market making y scalping de alta frecuencia | Requiere gestión activa de órdenes, cancelaciones frecuentes, más complejo de programar |
| AMM (Automated Market Maker) | Ejecución simple y garantizada, ideal para estrategias pasivas de LP, menos mantenimiento | Slippage significativo en órdenes grandes, pérdida impermanente, riesgo de liquidación por divergencia de precio |
Los informes de rendimiento de bots en producción muestran patrones claros: bots en Arbitrum experimentan 15% más errores RPC durante congestión de red que en Solana, pero Solana tiene 3 veces más reorgs que invalidan transacciones ya confirmadas. Linea ofrece la latencia más baja pero menor liquidez, causando slippage inesperado en órdenes medianas.
Las tasas de fallo varían dramáticamente por cadena y protocolo. Un bot de market making en un CLOB de Arbitrum puede tener 99.2% de uptime mientras el mismo bot en un AMM de Solana cae a 94.8% debido a reorgs frecuentes y divergencias de oráculo. Estos números importan cuando calculas rentabilidad esperada: 5% de downtime en momentos de alta volatilidad puede eliminar las ganancias de todo el mes.
Descubra Mithril Money para trading automatizado seguro
Después de implementar todas estas técnicas de monitorización, gestión de riesgo y manejo de casos extremos, te das cuenta de que construir y mantener infraestructura robusta de trading automatizado requiere experiencia de ingeniería además de conocimiento de mercados. Mithril Money resuelve exactamente este problema ofreciendo una plataforma completa donde la monitorización multinivel, gestión de riesgos y manejo de fallos ya están integrados desde el diseño.
La plataforma te permite enfocarte en la estrategia mientras Mithril maneja toda la complejidad técnica: timeouts de API, watchdogs, circuit breakers, ajuste dinámico de posición y detección de casos extremos funcionan automáticamente. Tus fondos permanecen en tu cuenta del exchange con ejecución no custodial, pero obtienes las ventajas de infraestructura profesional sin construirla tú mismo.
Si buscas alternativas para automatizar trading que combinen flexibilidad estratégica con robustez operacional, Mithril ofrece el balance ideal entre control y conveniencia. Prueba estrategias personalizables, monitoriza rendimiento en dashboards actualizados y ajusta parámetros en tiempo real sin preocuparte por si tu bot se colgará a las 3 AM.
Preguntas frecuentes
¿Cómo detectar fallos silenciosos en bots de trading?
Detecta fallos silenciosos implementando verificación explícita de cada acción crítica: después de colocar una orden, consulta el exchange para confirmar que existe con los parámetros correctos. Usa checksums en estados internos que compares contra el estado real del exchange cada 60 segundos. Configura alertas cuando discrepancias aparecen entre lo que tu bot cree que hizo y lo que realmente sucedió. Los logs detallados con timestamps precisos son imprescindibles para auditorías post mortem que revelan dónde comenzó el problema.
¿Qué métricas clave monitorear para bots en dex perpetuos?
Monitoriza P&L diario y acumulado para detectar deterioro de rendimiento temprano. Drawdown actual versus máximo histórico te dice cuánto riesgo has consumido. Presupuesto de riesgo restante indica cuánto más puedes perder antes de alcanzar límites. Tamaño de posición ajustado por ATR previene sobreexposición durante volatilidad extrema. Win rate y profit factor identifican cuándo tu estrategia deja de funcionar. Circuit breakers deben activarse automáticamente cuando drawdown alcanza 80% de tu límite máximo aceptable.
¿Cómo elegir entre clob y amm para bots en dex perpetuos?
Elige CLOB si tu estrategia requiere ejecución de alta frecuencia con slippage mínimo, como market making o scalping de momentum. Los order books ofrecen control preciso sobre precio de entrada y salida, ideal cuando márgenes son estrechos. Elige AMM si implementas estrategias pasivas de provisión de liquidez donde no necesitas ajustar posiciones frecuentemente. AMMs simplifican ejecución pero aumentan riesgos de pérdida impermanente y liquidación por divergencia de oráculos durante volatilidad extrema. La mayoría de bots profesionales operan en CLOBs porque el control de ejecución supera la complejidad adicional.
¿Cuánto downtime es aceptable para un bot de trading automatizado?
Bots profesionales deben mantener uptime superior a 99% mensual, lo que permite máximo 7 horas de downtime por mes. Durante períodos de alta volatilidad o eventos de mercado importantes, incluso 30 minutos de downtime pueden causar pérdidas significativas si pierdes oportunidades críticas o no puedes cerrar posiciones rápidamente. Implementa redundancia donde un bot de respaldo puede activarse automáticamente si el principal falla. Monitoriza tiempo promedio de detección de fallos y tiempo promedio de recuperación: ambos deben ser menores a 5 minutos para operaciones activas.
¿Con qué frecuencia revisar y ajustar parámetros de bots automatizados?
Revisa métricas de rendimiento diariamente antes de que los mercados abran para identificar problemas temprano. Ajusta parámetros semanalmente basándote en cambios en volatilidad, liquidez y condiciones de mercado. Realiza backtests completos mensualmente con datos recientes para verificar que tu estrategia sigue siendo efectiva en el régimen actual. Después de eventos de mercado significativos como cambios de tasas o noticias macroeconómicas importantes, revisa inmediatamente y considera reducir exposición hasta que las condiciones se estabilicen. La optimización excesiva es peligrosa: cambiar parámetros diariamente basándote en ruido de corto plazo destruye la consistencia estadística de tu estrategia.